L'angle mort
de la personnalisation
Ce billet est la traduction d’un article de recherche que j'ai initialement publié dans les actes de la conférence ACM Designing Interactive System (DIS 2019). L'article original est disponible ici en accès libre. La traduction a été remaniée pour rendre la lecture plus accessible en enlevant un petit peu de la lourdeur des papiers académiques.
Je souhaite remercier très chaleureusement tous les participants et les participantes à cette étude dont les témoignages constituent le cœur de cet article et sans lesquels aucun travail de design n’aurait été possible.
Résumé
La quantité d’information présente sur le web est trop importante pour que les individus puissent la traiter. Pour résoudre ce problème, les plateformes numériques ont commencé à déléguer à des algorithmes le soin d'éditorialiser, filtrer et de recommander des contenus à leurs utilisateurs. Cette question a donc généralement été perçue dans une perspective technique en tant que problème d’optimisation et a fait l’objet de très peu de considérations du point de vue du design. À travers 16 entretiens avec des personnes utilisant régulièrement une ou plusieurs plateformes numériques, j’analyse la manière dont les algorithmes de curation influencent leur expérience quotidienne et les stratégies qu’ils et elles développent pour tenter de les adapter à leurs besoins. Me fondant sur ces résultats empiriques, j’ai développé quatre propositions alternatives de design pour explorer les manières dont on peut intégrer les algorithmes de curation dans la toile plus large de nos interactions sur le web. En explorant des interactions pour contrer la nature binaire des algorithmes, leur unicité, leur anti-historicité ainsi que leur collecte implicite de données, je propose des outils pour combler l’écart entre les algorithmes et ceux à qui ils s’adressent.
Sommaire de l'article:
※ Alternative n°1 - Dépasser les listes et les grilles
※ Alternative n°2 - Diviser les algorithmes
※ Alternative n°3 - Matérialiser l'historique
※ Alternative n°4 - Expliciter les inférences
Introduction
Il y a trop d'information sur le web. Il y a d'ailleurs trop d'information dans nos vies en général. Et puisque l'on ne peut pas traiter toute cette information, la plupart des plateformes numériques sur lesquelles on passe notre temps ont commencé à mettre en place des algorithmes pour éditorialiser les informations qu'elles nous présentent. Ces algorithmes de curation peuvent prendre la forme d'algorithmes de recommandation, comme c'est le cas pour youtube ou amazon par exemple, ou bien ce sont des algorithmes de filtrage qui choisissent l'ordre des informations, comme sur le mur de facebook ou bien sur pinterest. Cette tendance à utiliser des algorithmes de curation pour adapter le contenu aux individus s'inscrit dans une tendance plus large à la personnalisation.
La personnalisation est un processus de modification de fonctionnalités ou d’interfaces pour l’adapter à chacun. Alors que la customisation est effectuée directement par la personne, la personnalisation est effectuée par le système en se basant sur des inférences. Cette personnalisation peut prendre de nombreuses formes mais on se focalise dans cet article sur les algorithmes de curation. Avec l'émergence de la personnalisation automatisée, les algorithmes de curation sont graduellement devenus des objets publics et plusieurs scandales ont émergés. Ils sont en effet accusés de créer des bulles de filtre, d'augmenter la polarisation politique vers les extrêmes et d'être biaisés envers les minorités.
Lorsque l’on observe les plateformes numériques actuelles, c’est comme si les designers avaient d’abord créé les interfaces et les interactions avant d’y ajouter des algorithmes après coup. Les algorithmes forment une couche séparée, sans existence visuelle. À l’inverse, ils réassignent les fonctionnalités existantes pour en extraire des données qu’ils utilisent ensuite pour générer des inférences. Leur invisibilité explique aussi pourquoi ils sont souvent considérés à raison comme des boites noires. L’approche traditionnelle pour résoudre ce problème a principalement été d’améliorer l’algorithme soit en utilisant plus de données, en obtenant plus de retours de la part des utilisateurs ou bien en expliquant les décisions prises. Ces approches sont centrées sur l’algorithme mais ne prennent pas en compte ce qui l’entoure.

Il y a un découplage total entre l'interface et les algorithmes de curation, empêchant toute communication directe entre les utilisateurs et l'algorithme. Ce dernier doit donc se contenter de tirer des inférences à partir d'actions qui ne lui sont pas destiné.
Dans cet article, on souhaite questionner les algorithmes en prenant en compte le fait qu’ils se déploient dans un tissu plus vaste, celui de l’interface utilisateur, derrière laquelle ils ont tendance à rester cacher. Je souhaite ici utiliser le design pour révéler et explorer cette relation en proposant des alternatives : des propositions conceptuelles qui ouvrent des possibilités d’interprétation. Le but n’est pas de proposer des solutions définitives mais au contraire de questionner l’isolement actuel des algorithmes en montrant combien de petites décisions de conception peuvent impacter les qualités et les limitations des algorithmes de curation.
Méthodologie
Pour nourrir les alternatives, il nous faut d’abord comprendre les pratiques actuelles. En s’appuyant sur les recherches existantes je m’attache à décrire en particulier les différentes manières dont les personnes interagissent, ou non, au quotidien avec les algorithmes de curation. Ce sont ces récits qui forment la base de mon travail de design en nourrissant des alternatives qui permettent de réfléchir de manière critique aux modalités d’interaction avec les algorithmes de curation. Quelques précisions sur les personnes qui ont participé à cette étude :
J’ai interviewé 16 participants à Tokyo et par Skype. J’ai cherché à interroger des personnes d’horizons et d’expertises différentes. Les participants et participantes ont de 23 à 40 ans et sont de nationalité française, néerlandaise, italienne, chinoise et japonaise. 5 participants se considèrent comme expert sur le web, 6 se considèrent comme ayant un niveau moyen et 5 considèrent qu’elles ont un niveau basique.
Dans un premier temps, j’ai donc conduit des entretiens semi-structurés qui ont chacun duré entre 1h et 1h30. J’ai commencé avec des questions concernant la perception et les interactions avec les algorithmes de curation de différentes plateformes que les participants utilisent régulièrement. J’ai également questionné les participants sur leurs habitudes de découverte de contenus et d’information, la manière dont ils gèrent le « trop plein d’information » et je leur ai demandé de comparer les différents systèmes de curation. J’ai enfin demandé des détails sur les différentes histoires, à la fois positives et négatives, qui m'ont été racontées à propos des algorithmes de curation. Pour cette étude, j’ai choisi de ne pas me focaliser sur un système ou une plateforme en particulier mais, au contraire, je me suis focalisée sur la façon dont différents algorithmes de curation et différents contextes affectent les réactions et les stratégies d’une même personne. Les plateformes qui ont été évoquées pendant ces entretiens incluent : youtube, spotify, facebook, twitter, instagram, pinterest, netflix, deezer, wechat, goodread, youporn et tinder. On a parfois également discuté d’outils tels que les fils RSS qui, bien qu’ils n’incorporent pas directement d’algorithmes étaient utilisés par les participants comme contre-exemples. Les entretiens ont été enregistrés et transcrits dans un second temps. J’ai également pris des notes écrites pendant les entretiens.
J’ai dans un premier temps analysé les interviews en utilisant une « analyse thématique » (thematic analysis). J’ai identifié des catégories d'histoires de manière inductive en me focalisant sur la manière dont ces histoires pouvaient nourrir un travail de design soit en paliant à des carences ou bien en s’inspirant de stratégies déjà déployées par les participants. J’ai ensuite groupé ces catégories émergentes et suis retournée dans les interviews pour appliquer ces catégories de manière constante. Comme le but de cette étude est avant tout de nourrir un travail de design, on ne présente pas les résultats de manière chiffrée parce que la fréquence ne détermine pas la valeur d'une histoire. Dans un contexte de design critique, des histoires dissonantes et des perspectives uniques sont tout aussi intéressantes que les histoires les plus communes.
À partir des entretiens, j’ai identifié quatre thèmes récurrents que je développe dans les paragraphes suivants. Pour chaque thème, je présente d’abord les récits des participants et leurs stratégies avant d’introduire et de discuter une proposition alternative qui tente de répondre aux problèmes et pratiques existantes.
Alternative n°1
Dépasser les listes et les grilles
L'un des problèmes identifiés par les participants était l'aspect binaire des algorithmes de curation : le fait qu'ils peuvent aussi bien cacher du contenu qu'en mettre en valeur. Comme P3 l'a expliqué, il rechigne à interagir avec l'algorithme de Netflix parce qu'il «ne saurait pas ce qu'il raterait s'il utilisait le pouce baissé ». Trois participants (P1, P3 & P13) ont également rapporté qu'ils visitaient régulièrement les profils de leurs amis sur les plateformes afin de s'assurer qu'ils n'avaient rien manqué parce qu'ils savent que l'algorithme ne leur montre pas tout. P1, par exemple, a réalisé, après plusieurs mois, que l'algorithme d'instagram ne lui avait pas montré les publications d'une de ses amies et qu'elle avait ainsi raté des moments importants.
L'approche principale pour contrer la binarité collatérale des algorithmes de curation a été d'apporter de meilleures explications sur les choix opérés afin d'aider les gens à comprendre pourquoi certains contenus sont sélectionnés. Cependant, expliquer pourquoi les algorithmes de curation cachent certains contenus est également un problème en soi. La limitation des algorithmes actuels n'est pas uniquement due à la nature ou la qualité de l'algorithme mais également à la manière dont les contenus sont présentés sur la plupart des plateformes. En effet, les contenus, qu’il s’agisse de tweets, de publications sur facebook ou bien de photos sur instagram, sont tous présentés sous le même format : en liste (le fil de facebook, la timeline de twitter, les vidéos suggérées par youtube...), en grille (les photos sur les profils d'instagram, les produits du catalogue amazon...) ou bien en un mix des deux approches.
Questionner le mur en tant que métaphore

Dans cette alternative, en explorant des mises en page plus complexes du contenu, l'algorithme peut proposer des sélections nuancées sur lesquelles l'utilisateur peut agir.
Je propose ici une première alternative pour questionner le fil en tant que moyen ubiquitaire de présenter l'information. Il s'agit ici de présenter le contenu qui n'a pas été retenu par l'algorithme de curation dans la marge, en utilisant une taille de corps typographique plus petite ou bien en affichant uniquement l'avatar de l'auteur. À l'inverse, le contenu sélectionné occuperait la partie la plus large de l'interface. Ce type de mise en page peut sembler familier. En effet, il s'agit ici d'une simple re-création de mise en page traditionnelle que l'on retrouve par exemple dans les journaux imprimés. Le processus d'éditorialisation signifie la priorisation de certaines informations par rapport à d'autres et cela peut être effectué de manières très diverses. L'information la plus importante peut être mise en avant en y joignant une image ou bien en agrandissant la taille de la police de caractère utilisée tandis que les informations jugées moins importantes a priori peuvent être minimisées et reléguées aux marges. Cependant, parce qu'il ne s'agit pas là d'un choix binaire, toute l'information reste accessible au lecteur, permettant d'éviter ce que P1 décrit comme «le coté pervers des réseaux sociaux... Parce que tu ne sais jamais ce que tu ne vois pas ».
Bien entendu, une limite de cette alternative est son manque d'accessibilité. Il ne s'agit bien évidemment pas d'implémenter cette alternative telle quelle, mais celle-ci permet en revanche de mettre en avant le rôle crucial que la mise en page et les différents outils du design graphique peuvent jouer pour proposer une éditorialisation plus nuancée. Dans les livres également, par exemple, nous avons entrainé nos yeux afin qu'ils puissent automatiquement discriminer les notes de bas de page, ce qui permet de présenter des réflexions annexes qui peuvent facilement être ignorées par les lecteurs pressés. On peut imaginer les manières dont ce type de mise en page permet d'enrichir les possibilités d'actions de la part des lecteurs. Il devient en effet possible de glisser le contenu du centre vers les marges pour indiquer au système que ce type de contenu nous intéresse moins. L'inverse est également vrai puisqu'il devient également possible de montrer qu'un contenu nous est particulièrement important.
Des contextes de lecture multiples pour de multiples types de contenus
Cette alternative fait écho à la stratégie personnelle de P15. Plutôt que d'utiliser les plateformes numériques dominantes pour s'informer, il a créé son propre lecteur RSS pour lequel il a développé deux flux parallèles. Le premier ne présente que les titres et concerne les articles de presse et de blog ; le second présente uniquement des photos et est dédié aux blogs de photographie qu'il suit. P15 a ainsi adapté le contexte de réception au type de contenu afin de faciliter sa navigation. P1 a également explicité sa frustration à propos de l'algorithme de Pinterest qui ne sait pas distinguer des contenus qu'elle définit comme « pragmatiques », tels que des recettes ou des poses de yoga, par rapport à des contenus plus « inspirationnels » tels que du mobilier ou des textures. Alors qu'elle apprécie toujours que l'algorithme lui recommande des contenus inspirationnels, elle aimerait pouvoir l'empêcher de lui recommander d'autres contenus de type pragmatiques puisqu'elle a déjà trouvé la recette qui lui fallait ou bien la pose de yoga qu'elle voulait essayer. P3 a également mentionné le fait que sur les différentes plateformes qu'il utilise, «il y a beaucoup de contenu qui ne sert absolument à rien, je ne fais rien avec, mais il fait partie de la décoration de mon environnement numérique, il doit être là parce que sinon on dirait que ce n'est pas chez moi ». Cette alternative peut nous aider à développer ce type d'environnement nuancé qui ne rejette pas certains contenus mais en revanche l'utilise comme un type de décoration en lui donnant le poids visuel adéquat.
Alternative n°2
Diviser les algorithmes
L'une des tensions les plus fortes était le fait que les participants voulaient dans certains contextes être maître du flux d'information qu'ils reçoivent alors qu'ils étaient tout à fait satisfaits de se laisser guider sur d'autres plateformes ou dans d'autres contextes. Dans le cas de P12, il accueillait avec plaisir les recommandations de youtube pour de nouvelles vidéos mais était très énervé lorsque Spotify choisissait la prochaine chanson pour lui. Cette tension a été identifiée depuis longtemps mais les réponses qui y ont été apportées ont principalement été d'améliorer l'algorithme en complexifiant le modèle et les inférences afin de le rendre plus sensible au contexte. Similairement à cette première tension, un autre problème est largement revenu dans les récits : la tension entre le confort et la découverte. P12 par exemple a raconté l'histoire d'une chanson découverte grâce à son cousin. Elle explique que spotify n'aurait pas pu la lui recommander parce que c'est « un genre de musique inspiré des années 30 » et elle n'écoute pas du tout ce genre de musique. P6 s'est également plainte que l'algorithme de youtube ne lui recommandait que de la musique d’Afrique de l'Ouest alors qu'elle était plutôt attirée par les chansons françaises à ce moment-là. Elle avait l'impression d'être dans un cercle vicieux car elle avait tendance à cliquer tout de même sur les recommandations de youtube, renforçant ainsi l'algorithme dans son choix de ne lui présenter que des musiques d’Afrique de l'Ouest.
Le problème de l'algorithme unique
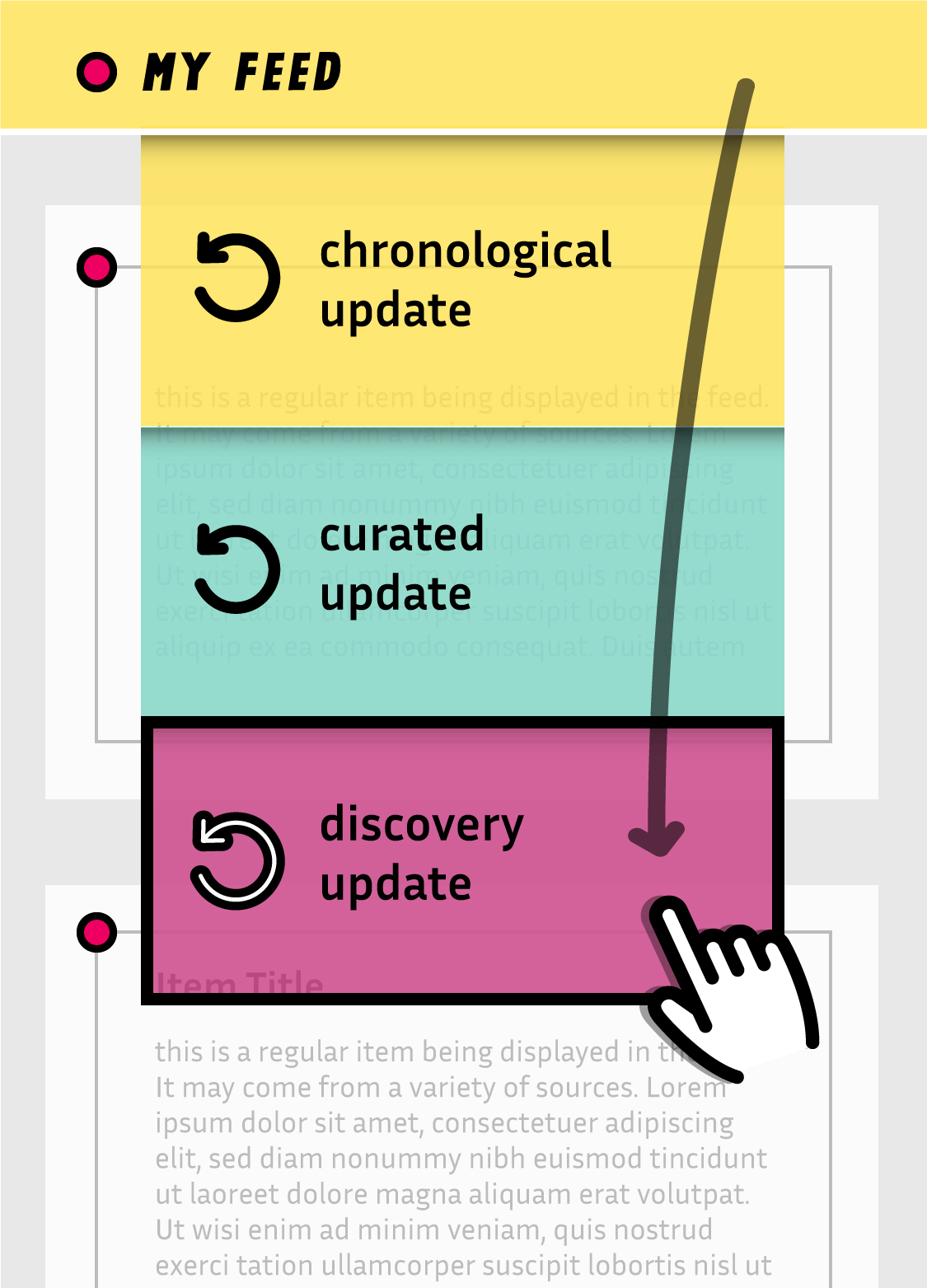
Dans cette alternative, le geste de tirer pour actualiser déroule plusieurs choix, il est possible d'actualiser sans algorithme, en utilisant l'algorithme actuel ou bien en utilisant un algorithme de découverte.
Pourtant, tenter de créer un algorithme de curation unique qui pourrait répondre à des désirs toujours divergents et contradictoires est une tâche vouée à l'échec, en particulier lorsque l'on pense que les principaux intéressés pourraient simplement indiquer leur intention. Plutôt qu'un algorithme unique, ce que montre les récits des participant·es c'est que des algorithmes différents correspondent à des moments différents de la vie, de la situation ou de l'humeur. Si l'on accepte l'idée de séparer les algorithmes en plusieurs variantes simplifiées pour répondre à différents types de navigations, on redonne alors le contrôle aux lecteurs et aux lectrices.
Suivant cette approche, dans cette alternative on repense l'interaction de « tirer pour actualiser » qui est l'une des principales façons de convoquer l'algorithme de curation en demandant explicitement plus de contenu. En décomposant cette interaction unique en plusieurs déclencheurs qui appellent chacun un type différent d'algorithmes de curation, on redonne la maîtrise du contexte au lecteur. Tirer un petit peu ne déclenche pas d'algorithme mais actualise simplement le fil en présentant les nouveaux contenus de manière chronologique. Tirer un petit peu plus déclenche alors un algorithme de curation similaire à celui utilisé aujourd'hui et qui infère les préférences à partir des activités de lecture précédentes. Tirer encore un peu plus déclenche un autre type d'algorithme de curation qui se concentre quant à lui sur des découvertes faisant appel à la sérendipité en affichant des contenus de sources jusque là inconnues.
Cette alternative n'a pas pour but de résoudre le problème des algorithmes de curation de manière directe, mais il remet le pouvoir dans les mains des lecteurs en leur permettant d'utiliser, ou non, différents types d'algorithmes en fonction de la situation et de l'humeur. Cette approche est différente d’un changement de paramètre dans l'optique de régler un algorithme unique car elle propose une manière de changer les paramètres, ou même la nature de l'algorithme à la volée, mettant à jour les actions se jouant derrière le voile de l'interface et renforçant le sentiment de control.
Être capable de déclencher différents algorithmes en fonction du contexte aiderait à prendre en compte les contextes d'usage extrêmement diverses révélés par les participants. Par exemple, le lecteur de flux RSS de P14 est extrêmement rassurant pour elle « car il n'y a pas de vous aimerez peut-être ceci et que personne ne va me pousser du contenu ». À l'inverse, P4 adore le fait qu'Instagram hiérarchise le contenu qui lui est présenté. Elle pense que ça lui permet de se détacher de l'application car l'application lui montre ce qu'elle aime en premier et qu'elle « n'a plus besoin de scroller indéfiniment ». De la même manière, P1 et P3 ont également mentionné la manière dont ils « laissent parfois l'algorithme gagner » sur youtube et cliquent sur les vidéos recommandés qu'ils n'avaient pourtant aucune intention de voir ou d'écouter ce jour-là: « Ok, je suppose qu'aujourd'hui c'est le jour de Georges Michael....» (P3).
Alternative n°3
Matérialiser l'historique
Le problème de l'insensibilité est également apparu dans le contexte de l'historique. P15 par exemple raconte comment l'un de ses anciens collègues lui a fait découvrir plusieurs morceaux de musique électronique, un style qu'elle n'avait jamais exploré auparavant. À ce moment-là, et grâce aux recommandations de youtube, elle a eu l'impression de découvrir un nouveau monde. Le problème, c'est que lorsqu'elle est retournée pour un moment écouter sa musique plus traditionnelle, elle a réalisé que « aussi tôt que j'écoute quelque chose de différent, il cesse de me suggérer les mêmes morceaux et je perds ce qu'il m'avait suggéré auparavant ». P12 était également très déçue par le fait que, lorsqu'elle utilise youtube pour mettre de la « musique de fête », après quelques recommandations adaptées, l'algorithme ramène toujours les chansons qu'elle écoute habituellement même si elles ne sont pas du tout dans l'ambiance de la soirée. Enfin, P14 explique comment ce problème l'a amené à arrêter d'utiliser Pinterest parce que même 5 ans après son mariage, il lui suggérait toujours des robes de mariée. Pour faire face à ce même problème P6 explique comment elle se force à écouter certains types de musique périodiquement pour forcer l'algorithme à lui recommander plus de ce type de contenu.
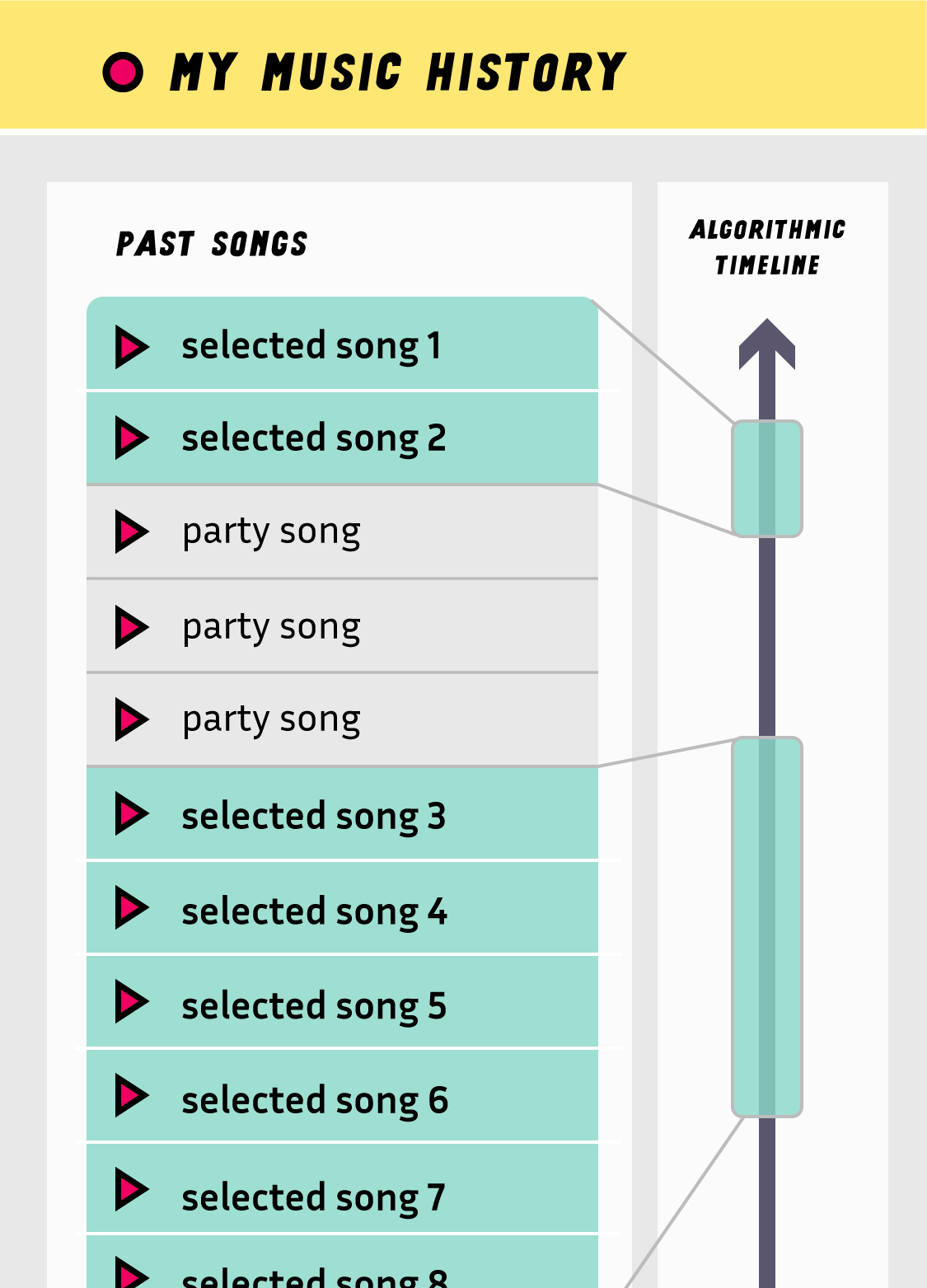
Dans cette alternative, il est possible de sélectionner ou bien de déselectionner des morceaux de musique spécifiques pour permettre à l'algorithme de faire des recommendations contextualisées.
Basé sur ces histoires et stratégies, on développe une alternative qui se concentre sur l'historique dans le contexte de la musique. Comme mentionné par la plupart des participants, la musique est un type de contenu hautement contextuel et fait souvent l'objet de phases en alternant des moments de partage entre amis, de ré-écoute et de découverte. Tous ces moments demandent de l'algorithme qu'il puisse proposer des recommandations adaptées. On propose alors de réifier l'historique d'écoute, c'est à dire faire de cet historique une visualisation interactive. Les personnes peuvent alors désélectionner certaines chansons afin qu'elles ne soient pas considérées par l'algorithme pour ses suggestions, ou bien, à l'inverse, revisiter ses écoutes passées et les sélectionner pour commencer un cycle de recommandation à partir de ces morceaux spécifiques.
Cette alternative complémente la précédente car dans les deux cas, elles donnent les moyens de sélectionner ou de manipuler les algorithmes en contexte. C'est ce que P10 attend d'un système de recommandation car les algorithmes généraux « ne fonctionnent pas pour moi parce que j'écoute trop de styles de musique différents ». À l'inverse de ses playlists qui lui offrent des atmosphères variées mais spécifiques, l'algorithme de Deezer mélange du hard rock avec de la musique calme ce qui l'empêche de développer une humeur particulière.
Alternative n°4
Expliciter les inférences
À cause de la séparation des couches algorithmiques et d'interaction, les participants rencontrent des problèmes pour communiquer avec l'algorithme. P11 raconte qu'elle « passe son temps à essayer de contrôler ce que je vois et c'est très frustrant parce que je ne peux pas le faire avec la nuance que j'aimerais ». Il y a également beaucoup de collisions entre les fonctionnalités originelles des plateformes et la manière dont elles sont utilisées pour nourrir l'algorithme. Chaque interaction avec la plateforme est jugée de la même manière alors que les participants y assignent des sens très différents. P1 raconte ainsi : « je souhaitais juste sauvegarder cette séquence de yoga pour garder le lien, mais lorsque je suis revenue sur pinterest, il a commencé à me montrer plein de trucs liés au yoga ». Pour elle, le fait d'épingler ce contenu signifiait le conserver alors qu'il avait été interprété par l'algorithme comme : « donne-m’en plus ». P12 raconte également comment l'algorithme de youtube lui recommandait toujours les mêmes deux chansons : « pendant un moment, j'écoutais la première tous les jours, mais la seconde, c'est uniquement parce qu’il se trouvait que c'était la suivante [...] mais maintenant, l'algorithme pense que c'est aussi ma préférée. »
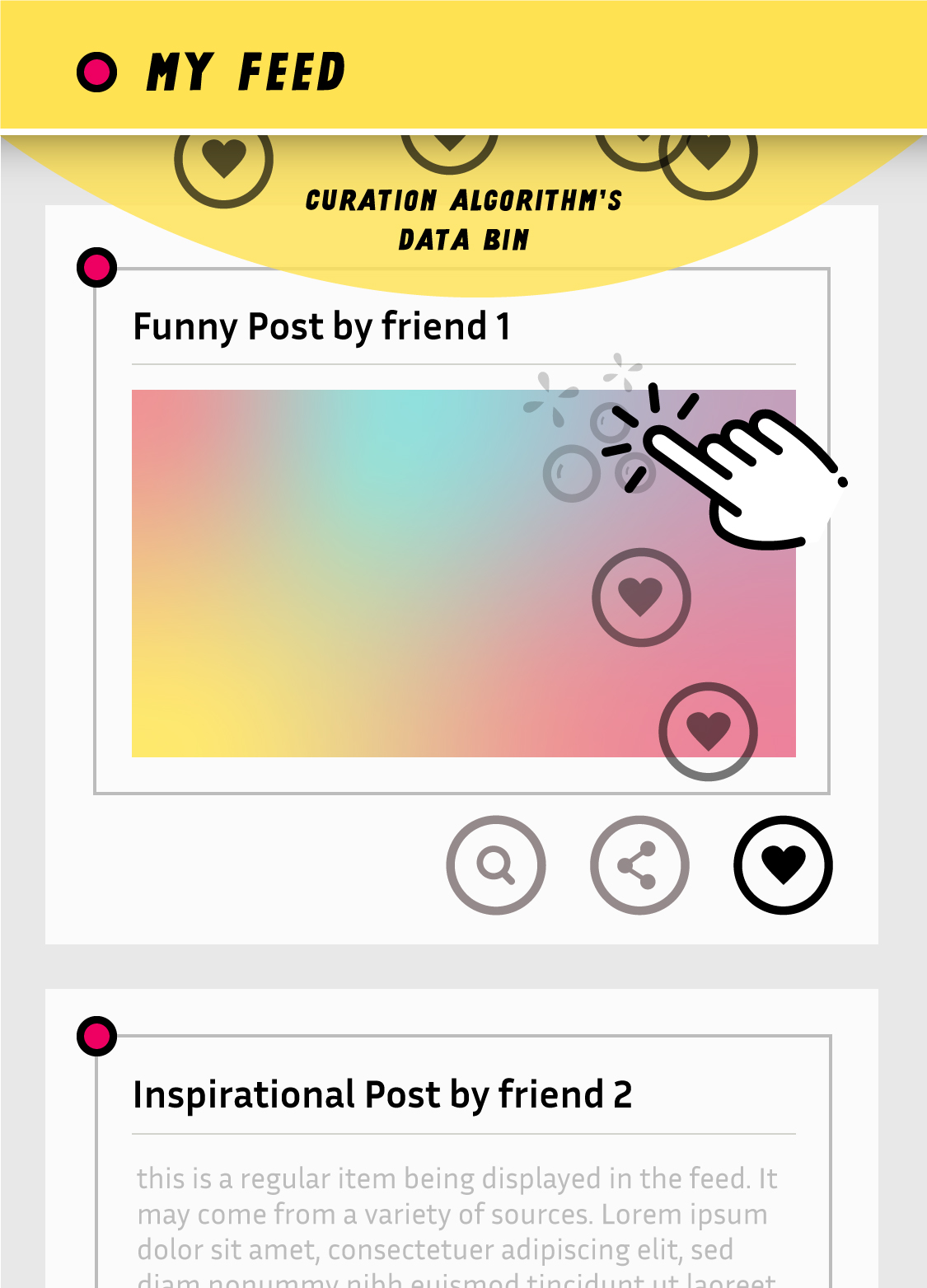
Dans cette alternative, chaque action utilisée par l'algorithme est d'abord révélée à l'utilisateur qui peut choisir de ne pas la partager ou bien de la modifier.
Pour contrer ces problèmes de communication, les participants tentent d'influencer l'algorithme en réassignant certaines fonctionnalités de l'interface. Par exemple, P1 raconte qu'elle s'était rendue compte que l'algorithme ne lui montrait plus les postes de gens qu'elle suivait. Elle a ainsi décidé d'utiliser le « like » sur instagram non pas comme un signe d'appréciation d'une image en particulier, mais parce qu'elle veut « vraiment être sûre qu'il me montre les publications de cette personne ». Les participants modifient ainsi leurs manières d'interagir en ligne dans le seul but d'envoyer le bon message aux algorithmes de curation. Par exemple, P3 explique : «je passe des chansons même si à la radio elles ne m'auraient pas dérangé, mais comme ce n'est pas exactement ce que je recherche, j'espère que l'algorithme lira ça comme : 'moins de ce type de musique' », tout en précisant qu'il ne sait pas si ce comportement avait véritablement un effet.
Dans cette alternative, on révèle la collection d'information par les algorithmes. En utilisant une nouvelle fois la réification, on transforme des actions auparavant invisibles en objets interactifs. Par exemple, lorsque l'on clique sur le bouton « j’aime », une version translucide de cette information se dirige vers le haut de l'application, pour représenter le fait d'envoyer cette information à l'algorithme. Comme cette transmission d'information est ralentie, elle permet aux personnes de la toucher pour la supprimer par exemple. Cette alternative questionne ainsi la notion de vie privée puisque dans cette alternative, le consentement face au partage des données devient ainsi perpétuellement révocable en contexte.
Les participants souhaitaient également avoir accès à de plus nombreux types de recommandations. Par exemple, P3 utilise un VPN pour localiser son Spotify en France parce que la musique est éditorialisée différemment dans ce pays. Cette stratégie n'est pour l'instant pas acceptée par Spotify car la plateforme le déconnecte constamment. Pour enrichir cette alternative, on peut étendre le principe du partage d'information avec l'algorithme à d'autres types d'information, simplement en glissant ces informations vers un réceptacle dédié. Dans ce contexte, glisser l'avatar d'une personne pourrait signifier : « je veux voir toutes les publications de cette personne » alors que glisser le hashtag pourrait signifier : « je veux voir les publications liées à ce sujet ».
Conclusion
Avec ces quatre alternatives fictives, j’ai seulement effleuré la surface d’une possible intégration des algorithmes de curation dans les pratiques. Ce travail m’a notamment permis de voir comment les algorithmes de curation ont co-évolués avec la simplification des interfaces en se rendant nécessaires pour contrer l’appauvrissement de l’organisation visuelle de l’information sur le web. Il me semble que ce n’est pas un hasard si ces algorithmes de curation ont d’abord été adoptés par des plateformes comme amazon ou facebook qui affichent leur contenu sous forme de grille ou de liste. L’architecture de l’information et la mise en page sont des éléments cruciaux dans la manière dont les algorithmes fonctionnent aujourd’hui. En refusant d’utiliser les outils d’organisation offerts par le design graphique et le design d’interaction, on doit se restreindre à des manières extrêmement limitées d’interagir avec le contenu et les algorithmes. Les problèmes actuels sont ainsi à rechercher autant dans un manque de design que dans un défaut des algorithmes.
Bien entendu, les alternatives proposées ici ne sont pas destinées à être implémentées telles quelles. Elles sont en soi extrêmement limitées et peuvent créer leurs propres biais car elles ne modifient qu’à la marge l’architecture des plateformes existantes. Dans le contexte de ce projet, j’ai délibérément choisi de proposer des changements minimaux pour montrer qu’ils pouvaient déjà complètement transformer notre regard. Pourtant, je sais délibérément que l’espace de conception est bien plus vaste et qu’il faut explorer des alternatives bien plus radicales.
Il me faut également mentionner le fait que ce projet et ces alternatives ont été développées à partir de l’hypothèse selon laquelle il peut exister un véritable partenariat entre les algorithmes et des humains. J’ai délibérément laissé de coté le fait que l’objectif pour les gens qui développent ces algorithmes est bien souvent très différent des objectifs des personnes qui vont les utiliser. Si l’on envisage de développer de telles alternatives en situation réelle, alors cette question devient centrale et il devient nécessaire de questionner le modèle d’affaire de la plateforme qui déploie l’algorithme. Pourtant, et malgré cette situation, de nombreux autres acteurs aux modèles d’affaire très différents peuvent vouloir déployer des algorithmes de curation et il est crucial qu’ils puissent prendre conscience des marges de manœuvre et des alternatives possibles.
Pour conclure cet article, je tiens à remercier une nouvelle fois l’ensemble des participants et des participantes qui ont donné de leur temps pour que ce projet puisse voir le jour.
Bibliographie sélective
Quelques références sur la perception des algorithmes par le public
[※] Bucher, T. 2017. The algorithmic imaginary: exploring the ordinary affects of Facebook algorithms. Information, Communication & Society. 20, 1 (Jan. 2017), 30–44.[※] DeVito, M.A. et al. 2017. “Algorithms ruin everything”: #RIPTwitter, Folk Theories, and Resistance to Algorithmic Change in Social Media. Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems - CHI ’17 (Denver, Colorado, USA, 2017), 3163–3174.
[※] Dourish, P. 2016. Algorithms and their others: Algorithmic culture in context. Big Data & Society. 3, 2 (Dec. 2016)
[※] Eslami, M. et al. 2016. First I “like” it, then I hide it: Folk Theories of Social Feeds. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems - CHI ’16 (Santa Clara, California, USA, 2016), 2371–2382.
[※] Rader, E. and Gray, R. 2015. Understanding User Beliefs About Algorithmic Curation in the Facebook News Feed. Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems - CHI ’15 (Seoul, Republic of Korea, 2015), 173–182.
[※] Witzenberger, K. 2018. The Hyperdodge: How Users Resist Algorithmic Objects in Everyday Life. Media Theory. 2, 2 (Dec. 2018), 29–51.
Quelques références sur la méthode de design
[※] Gaver, B. and Martin, H. 2000. Alternatives: exploring information appliances through conceptual design proposals. Proceedings of the SIGCHI conference on Human factors in computing systems - CHI ’00 (The Hague, The Netherlands, 2000), 209–216.[※] Dove, G. et al. 2017. UX Design Innovation: Challenges for Working with Machine Learning as a Design Material. (Feb. 2017), 278–288.
[※] Pierce, J. and DiSalvo, C. 2017. Dark Clouds, Io&#!+, and [Crystal Ball Emoji]: Projecting Network Anxieties with Alternative Design Metaphors. (2017), 1383–1393.
[※] Sengers, P. and Gaver, B. 2006. Staying Open to Interpretation: Engaging Multiple Meanings in Design and Evaluation. Proceedings of the 6th Conference on Designing Interactive Systems (New York, NY, USA, 2006), 99–108.
[※] Tanenbaum, J. 2014. Design Fictional Interactions: Why HCI Should Care About Stories. interactions. 21, 5 (Sep. 2014), 22–23.
[※] Alvarado, O. and Waern, A. 2018. Towards Algorithmic Experience: Initial Efforts for Social Media Contexts. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems (New York, NY, USA, 2018).
[※] Baumer, E.P. 2017. Toward human-centered algorithm design. Big Data & Society. 4, 2 (Dec. 2017).
Quelques références critiques sur les algorithmes de curation
[※] Bozdag, E. 2013. Bias in algorithmic filtering and personalization. Ethics and Information Technology. 15, 3 (Sep. 2013), 209–227.[※] Feuz, M. et al. 2011. Personal Web searching in the age of semantic capitalism: Diagnosing the mechanisms of personalisation. First Monday. 16, 2 (Feb. 2011).
[※] Schou, J. and Farkas, J. 2016. Algorithms, Interfaces, and the Circulation of Information: Interrogating the Epistemological Challenges of Facebook. KOME. 4, 1 (2016). DOI:https://doi.org/10.17646/KOME.2016.13.
[※] Zuboff, S. 2015. Big other: Surveillance Capitalism and the Prospects of an Information Civilization. Journal of Information Technology. 30, 1 (Mar. 2015), 75–89.